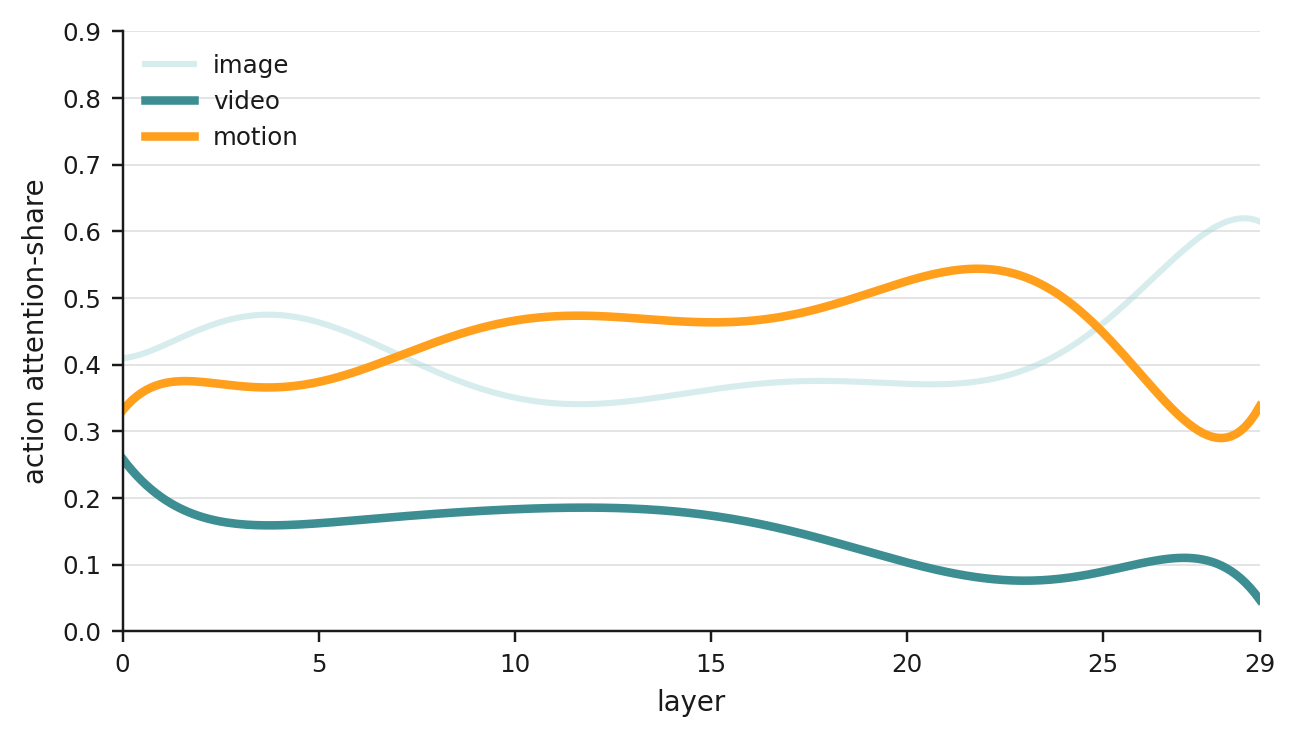Pretrained video generation models distill internet-scale motion priors into robot policies, but full video is a
redundant signal for action prediction. We argue that dense 3D motion is the medium through which video pretraining
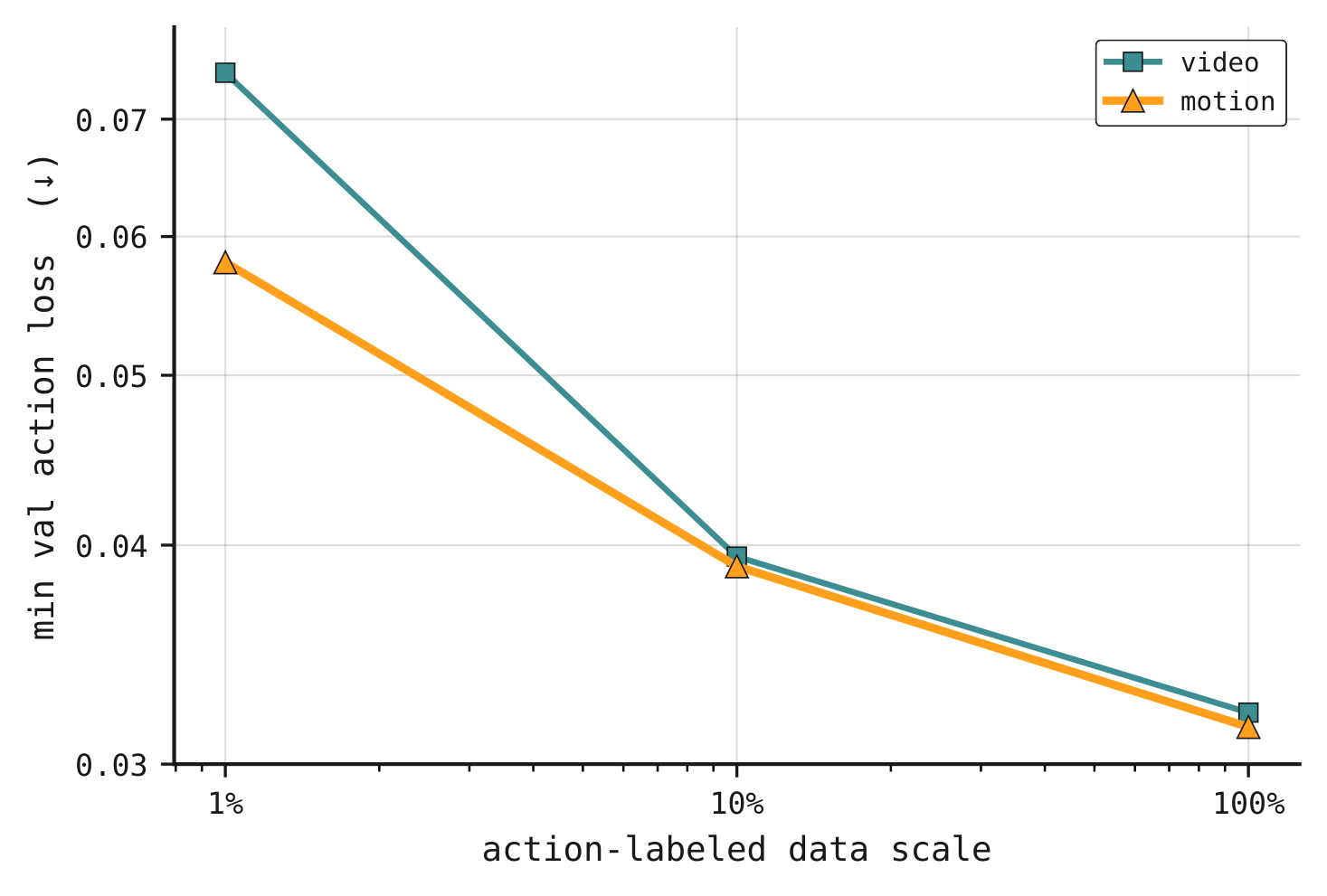
best transfers to robot actions, and that predicting motion rather than video affords better sample-efficiency for
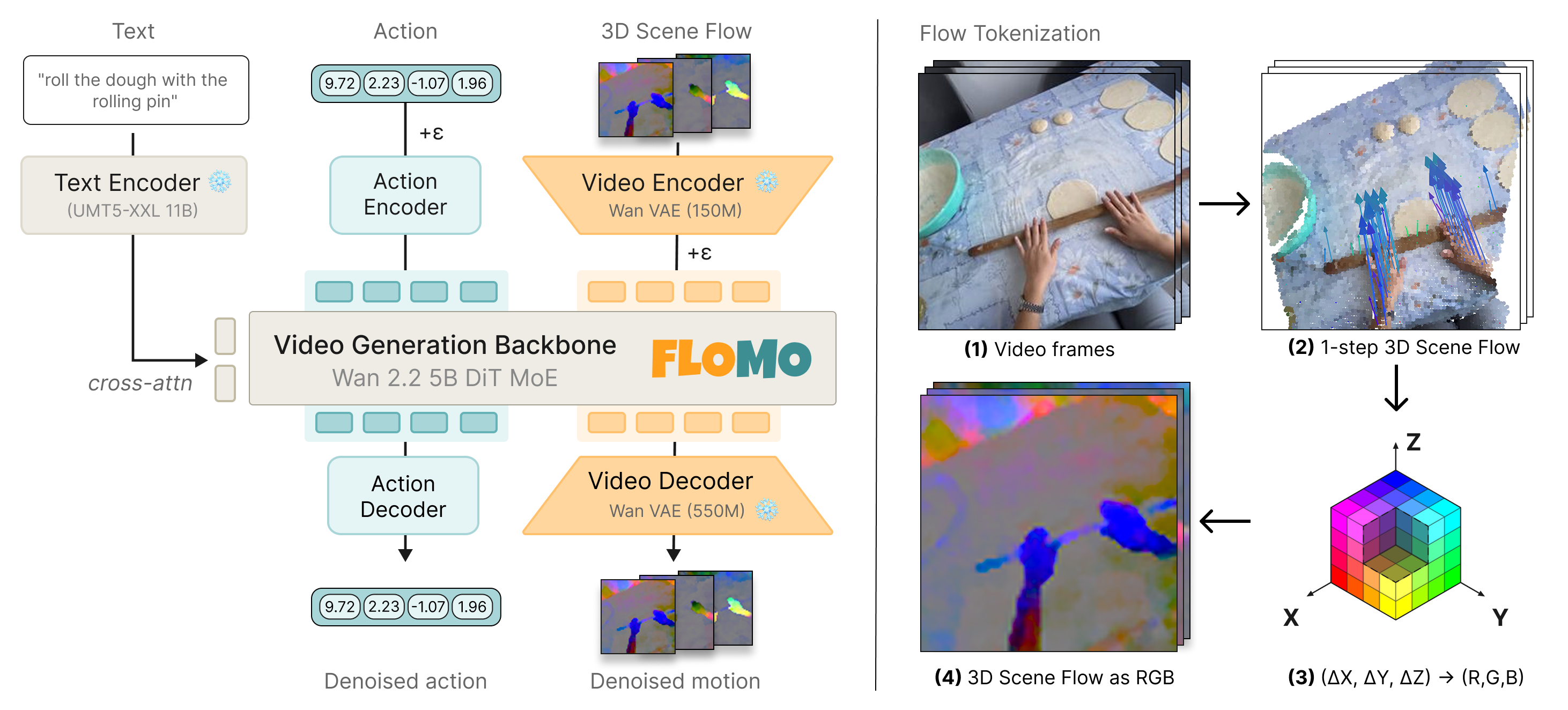
action prediction. FloMo is a 5B video-generation model fine-tuned to predict 3D scene-flow and action tokens.
Rendering scene flow as RGB and encoding it into the same latent space as video enables a pretrained video generation
backbone to efficiently adapt to predict 3D scene flow. Co-trained on action-free human video and action-labeled
robot teleoperation data, our model benefits from human-video pretraining and generalizes to unseen objects, motion
primitives, and tasks.
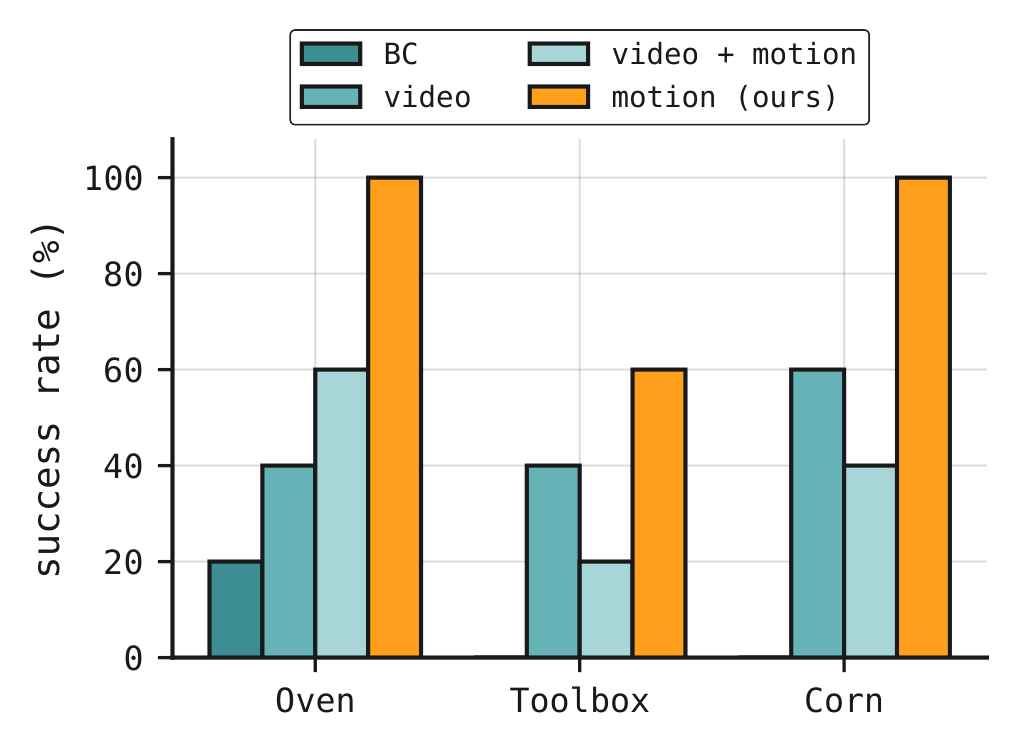
Removing the scene flow prediction objective degrades out-of-distribution generalization, while adding a video
prediction target alongside motion lowers policy success rather than improving it. When motion, video, and action
are predicted jointly, action tokens attend far more to motion than to video, suggesting that predicting video
wastes model capacity. Together, these results indicate that motion mediates the transfer from video pretraining
to action.